Scaling just a bit
Josip Maslać
Hey you!
if you didn’t have the chance to watch me present these slides at the conference fear not!
there should be a video available at: 2016.webcamp.si
you can press letter S and get more or less everything I said
Me
Josip Maslać
developer
average GNU/Linux user
founder & co-owner
nabava.net
#shamelessadvertising

wanted: hr_HR ⇒ sl_SL translators
Our situation

Monthly analytics
250k unique visitors
450k visits
1 900k pageviews
99% site’s content is dynamic
Initial goal

requirement ⇒ minimal change to the application code
Distributing load

all services run on both servers but just some are "active"
Improving

mysql@srv2 is "active" ⇒ everybody connects to that node
Server 2 fails

change database connections on the fly
Reverse proxy/loadbalancer
our choice High Availability Proxy - HAProxy
software
free, very fast and reliable solution offering high availability, load balancing, and proxying for TCP and HTTP-based applications
important terms:
frontend
backend
HAProxy frontend

HAProxy frontend & backend

high availability
Loadbalancing

high availability & scaling
Applied to our use case

Our status

Reminder
Database

Database

Winning?

eh, so so…
Scaling relational DBs
is hard!!
hasn’t anyone done this before?!
U in CRUD is the (biggest) problem
in our case
web apps typically have read/write radio around 80/20
Master-slave replication

Master-slave replication

Scaling

separate write & read operations ⇒ non-trivial task
Back to our situation

Our situation

Master-master replication
replication is done in both directions
painfully hard
concurrency issues
we "ignored" the problems by:
using active/passive approach
in a given moment only one database node can be used
Active/passive ⇒ this

Active/passive ⇒ xor this

Active/passive
not really scaling
but at least we got high availability
for our use case "good enough"
What about Solr
has it’s own solution ⇒ SolrCloud
requires min. of 3 nodes/servers ⇒ no go
our app - minimal effort to separate write & read operations
so we used standard master-slave replication
Our status

File synhronization
[again] Hasn’t anyone done this before?!
Manually syncing (rsync/lsync) - problems:
[again] concurrency issues
who should overwrite who
Solution:
GlusterFS
scale-out network-attached storage file system
main use cases:
storing & accessing LARGE amounts of data
ensuring high availability (file replication)
transparent to applications
easy to setup and use
GlusterFS - TL;DR
knows the concept of a volume
different types of volumes (distributed, replicated, stripped…)
replicated volume - file replication & synhronization:
when a file is updated Gluster takes care it is updated on all the servers it should be updated (in a synchronous & transactional manner)
Replicated volume
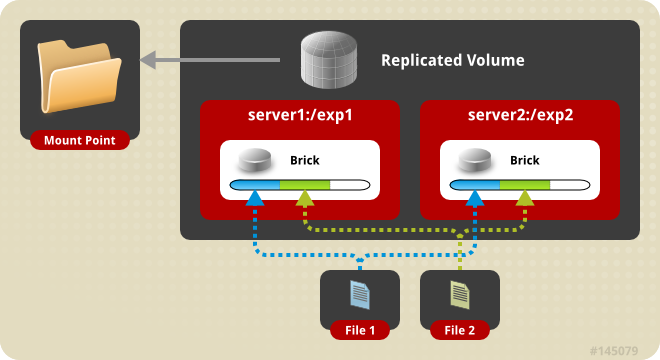
replication: synchronous & transactional
GlusterFS
no time for details
why not Amazon S3 (or similar)
$$$
requires (significant?) updates to the application code
Are we done yet?!

Result
high availability
scaled a bit
almost didn’t touch app code (changed 5~10 lines)
learned a LOT
We didn’t cover
a BUNCH of stuff
monitoring
logging
sessions issues <> loadbalancing
server provisioning
containerisation (docker)
and a lot more…
One more thing…
I lied
Our actual setup

Thank you
Questions?
Talk
Contact info
Don’t forget